Decoding Emotion from EEG: Introducing NOVA
Today, we are introducing NOVA (Neural Observations of Video-evoked Affect), a large-scale dataset of emotion-evoking videos paired with EEG recordings.

Reese Kneeland
2026-02-17
Understanding how the human brain represents visual information is a foundational goal for both neuroscience and artificial intelligence. While recent years have seen breakthroughs in reconstructing images from fMRI scans, translating these capabilities to accessible, portable hardware like EEG (Electroencephalography) has remained a significant challenge.
Today, we are introducing ENIGMA (EEG Neural Image Generator for Multi-subject Applications). ENIGMA is a new multi-subject decoding model that reconstructs seen images from EEG signals with state-of-the-art accuracy. By learning a shared “visual language” across different brains, the model can adapt to a new user in minutes rather than hours, bringing practical Brain-Computer Interfaces (BCIs) closer to reality.

The primary bottleneck for practical EEG decoding has historically been calibration time. Because every brain is unique—with different cortical folds and signal patterns—previous models required training a new system from scratch for each person. This process typically demands hours of tedious data collection, making it impractical for real-world applications like clinical communication or consumer electronics.
ENIGMA fundamentally changes this paradigm. By pre-training on a large group of subjects, the model learns generalizable features of brain activity. This allows it to rapidly fine-tune to a new individual's unique neural signature. In our testing, we found that recognizable semantic reconstructions begin to emerge with as little as 15 minutes of data from a new user.

This efficiency is achieved through a novel architectural design. Unlike previous approaches that rely on heavy, distinct models for every user, ENIGMA utilizes a unified “spatio-temporal backbone”. This shared network extracts robust features from the raw EEG signal across all users.
To handle individual differences, we introduce lightweight “latent alignment layers”. These small modules act as translators, mapping a specific user's unique neural patterns into a universal latent space understood by the model. Once aligned, these signals are projected into a semantic visual space (CLIP) and reconstructed into high-fidelity images using SDXL Turbo. This design allows us to share over 99% of the model parameters across users, drastically reducing computational overhead.
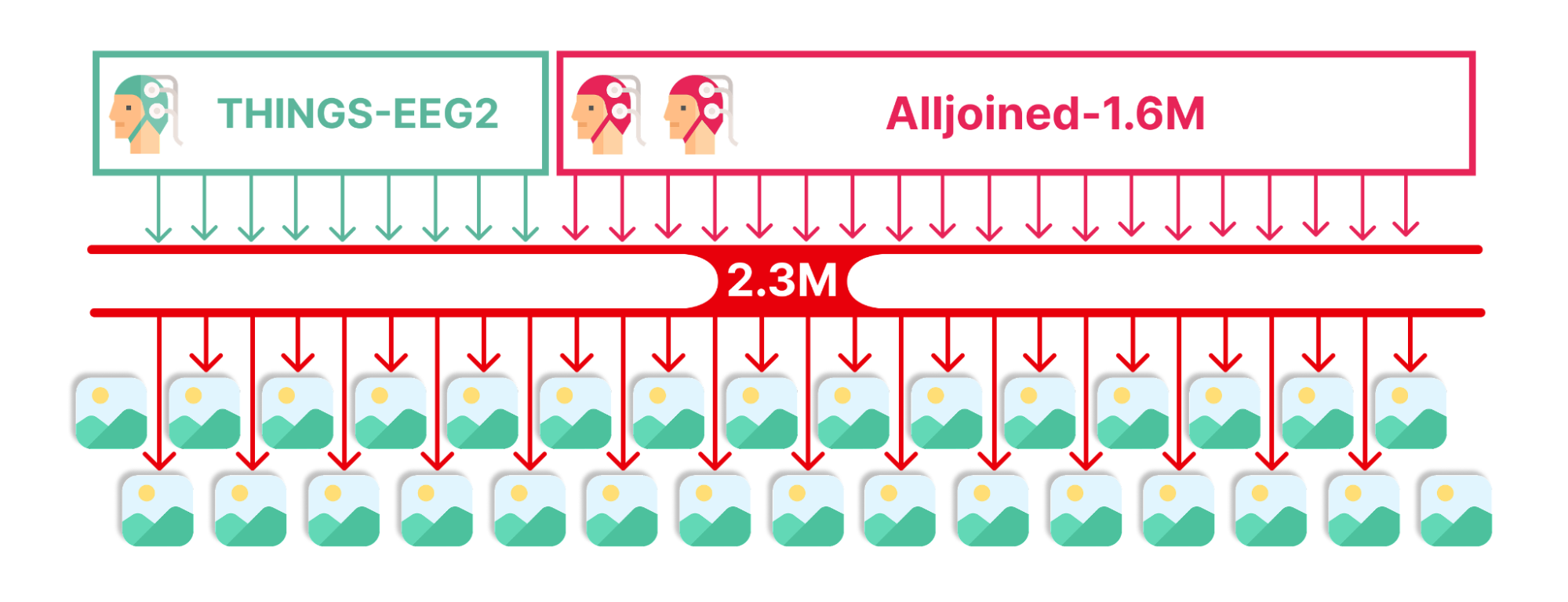
Crucially, this efficiency does not come at the cost of performance. We evaluated ENIGMA on both research-grade datasets (THINGS-EEG2) and our own consumer-grade dataset (Alljoined-1.6M).
The reconstructions demonstrate a high level of semantic robustness. While pixel-perfect reconstruction from EEG remains a challenge due to the noisy nature of the signal, ENIGMA successfully captures the concept of the visual stimulus. Whether the user is looking at a sheep, a piece of fruit, or a piece of furniture, the model generates a visually coherent image matching that category. Most importantly, this performance remains robust even when using affordable, consumer-grade headsets, which often cause complex legacy models to fail.

The advantage of our multi-subject approach becomes clearest when looking at the data requirements. By leveraging the knowledge learned from other subjects, ENIGMA effectively transfers learning to new contexts.
Our scaling analysis confirms that pre-trained models significantly outperform those trained from scratch, particularly in “low-data” regimes. At the 15-minute mark, where traditional models often fail to produce any identifiable images, ENIGMA is already capable of generating meaningful outputs. This steep performance curve is the key to unlocking BCIs that users can simply put on and use almost immediately.
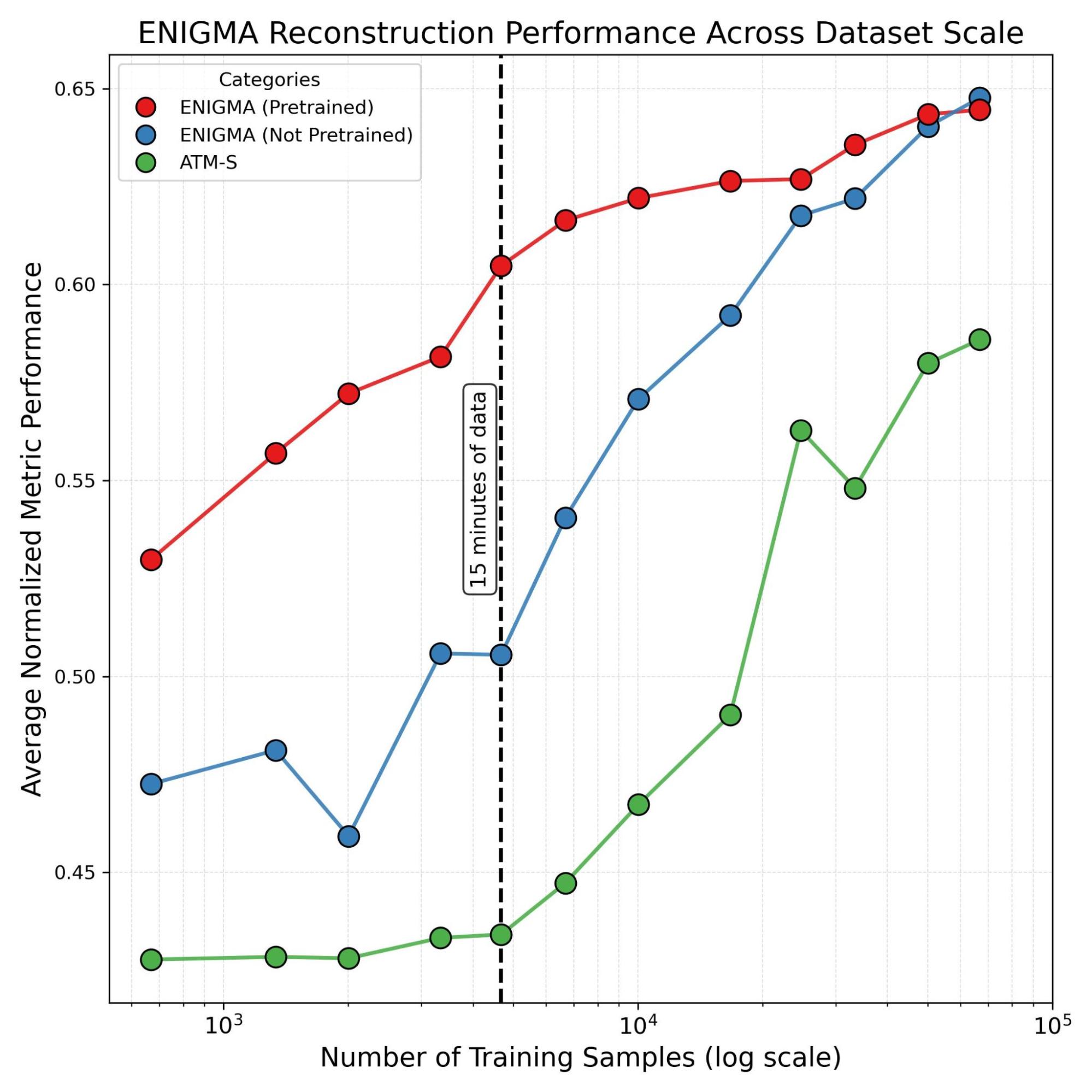
ENIGMA represents a shift from “single-subject, lab-only” experiments to “multi-subject, real-world” applications. By reducing the calibration bottleneck and reducing parameter counts by orders of magnitude, we are laying the groundwork for BCIs that are not only powerful but also portable and accessible to people in impactful real world scenarios.
We are committed to developing this technology responsibly and transparently. We believe that non-invasive brain decoding has the potential to transform assistive technology and redefine the way humans interact with our devices, and we look forward to seeing how the community builds upon this work.
Today, we are introducing NOVA (Neural Observations of Video-evoked Affect), a large-scale dataset of emotion-evoking videos paired with EEG recordings.

Today, we are formally introducing Alljoined-1.6M, a large EEG-image dataset comprising over 1.6 million visual stimulus trials collected from 20 participants on consumer-grade hardware.
Today, we are introducing ENIGMA (EEG Neural Image Generator for Multi-subject Applications). ENIGMA is a new multi-subject decoding model that reconstructs seen images from EEG signals with state-of-the-art accuracy.