Decoding Emotion from EEG: Introducing NOVA
Today, we are introducing NOVA (Neural Observations of Video-evoked Affect), a large-scale dataset of emotion-evoking videos paired with EEG recordings.

Jonathan Xu
2026-03-09
Today, we are formally introducing Alljoined-1.6M, a large EEG-image dataset comprising over 1.6 million visual stimulus trials collected from 20 participants on consumer-grade hardware. As the largest consumer-grade EEG-image dataset to date, it provides a foundation for analyzing the tradeoff between dataset scale and hardware quality in neural decoding.
In this post, we share our analysis of the dataset to contribute to the field of neural decoding. We find that deep neural networks can extract semantic content from consumer EEG and that AI scaling laws do apply to low-SNR hardware. However, the scaling exponent is significantly lower. Because of this lower signal-to-noise ratio, consumer-grade data yields smaller incremental gains. As we train on more data, this penalty compounds; by the upper bounds of our dataset, achieving the same accuracy requires over 20x the data volume of lab-grade hardware.
The ability to decode rich visual information from the human brain is a critical frontier in brain-computer interface (BCI) research. This has prompted a push to drastically scale brain scan datasets for machine learning models, particularly in the EEG domain. Naturally, this raises questions about the tradeoff between dataset size and signal quality. Can sheer scale overcome the noise of affordable hardware to facilitate state-of-the-art deep neural decoding?
Answering these questions allows us to understand whether emergent behaviors and improved performance manifest as we scale dataset size, analogous to trends in text and vision domains. Because neural data involves complex nuances in hardware, experiment design, and signal processing, evaluating dataset quality in isolation is difficult. Therefore, our work is motivated by reproducing a popular baseline dataset, Things-EEG2, using consumer-grade hardware to establish a direct comparison.
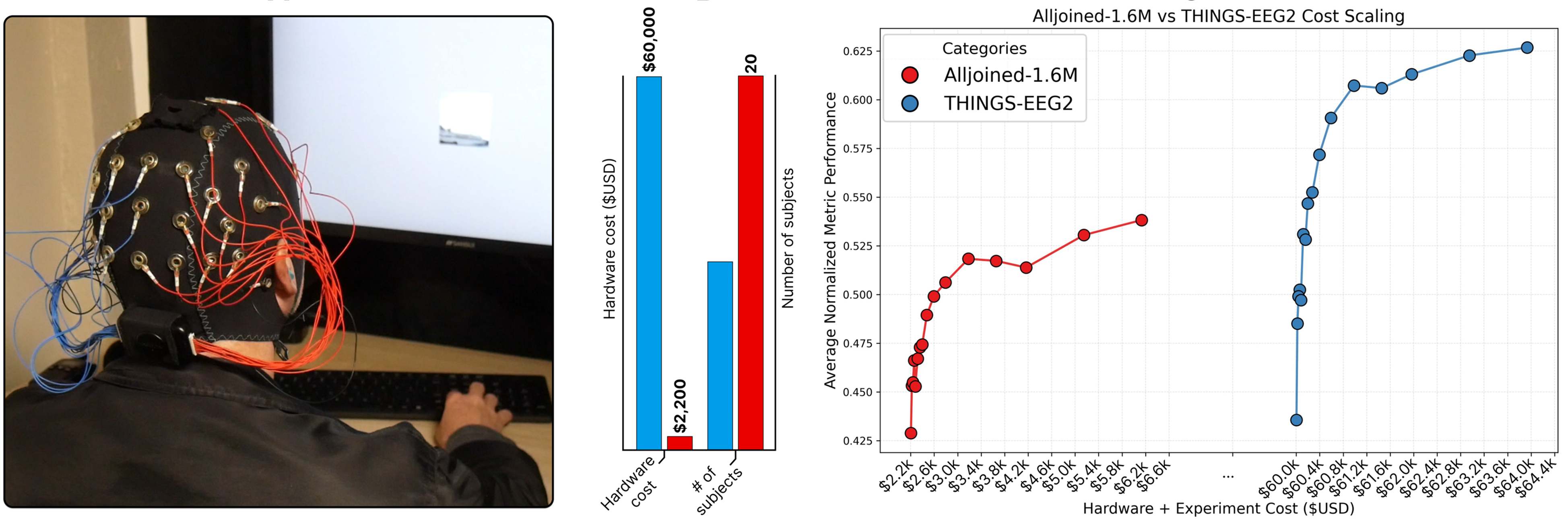
To directly compare consumer and professional EEG hardware, we recreated a baseline experiment under identical conditions using drastically different equipment:
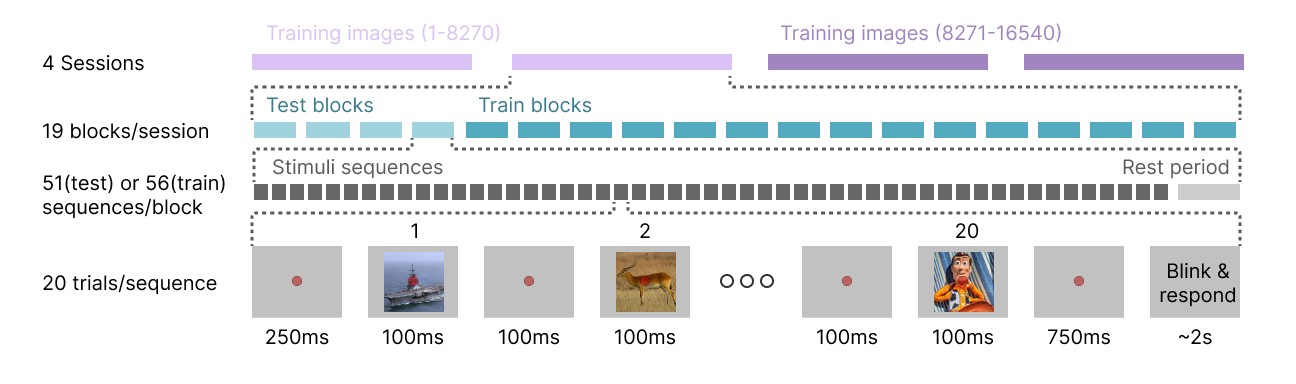
While consumer-grade devices lower the financial barrier to entry, they traditionally suffer from a reduced signal-to-noise ratio (SNR). To validate the physiological authenticity of our consumer-grade data, we conducted several analyses prior to training EEG-to-image reconstruction models.
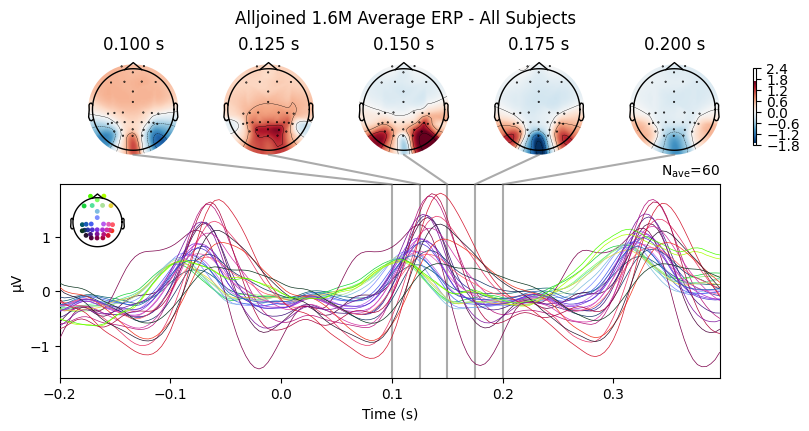
1. ERP analysis We divided the continuous EEG recordings into one-second segments, starting at the exact moment a participant saw a new image. By averaging these segments together, we extracted Event-Related Potentials (ERPs) to observe global signal patterns. Consistent with visual processing, we expected the strongest activity in the occipital cortex. As shown in our analysis, occipital channels exhibited a distinct early visual response, with a negative deflection at 100ms followed by a prominent positive peak between 125ms and 150ms. This confirms the hardware captured physiologically meaningful data related to visual processing.
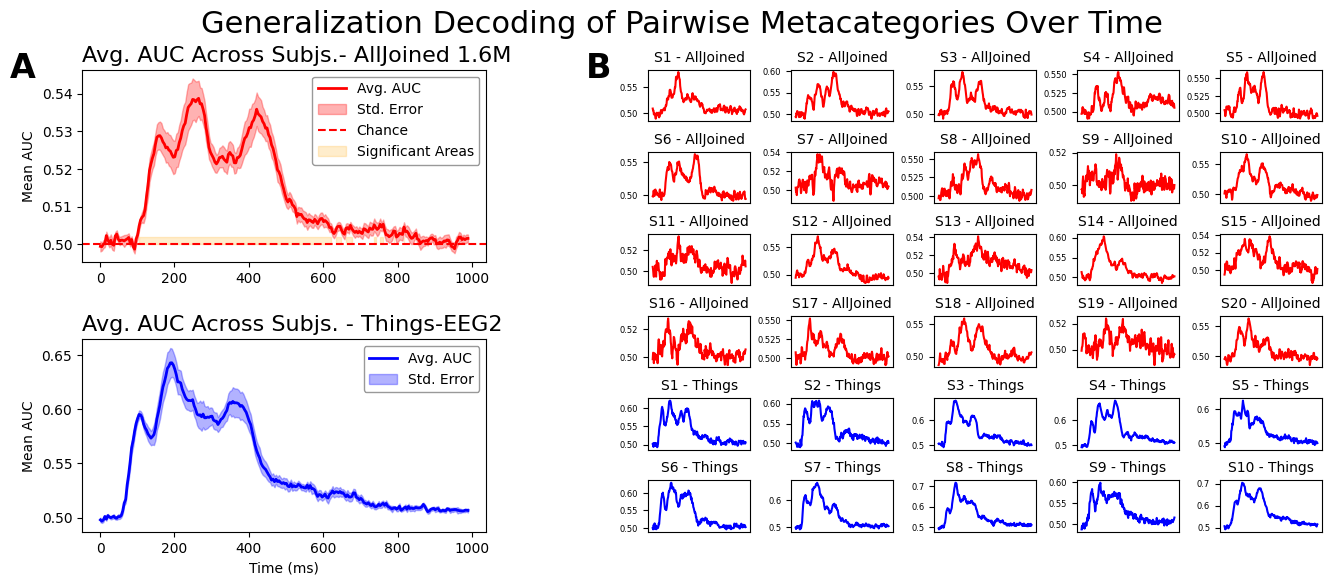
2. Pairwise LDA decoding To confirm statistically significant differences between image categories, we conducted pairwise linear discriminant analyses. In both Alljoined-1.6M and Things-EEG2, decoding performance was well above chance. Notably, the successful decoding clusters focus mostly on the 220 ms to 400 ms window, a timeframe we know is associated with later-stage, higher-level visual processing.
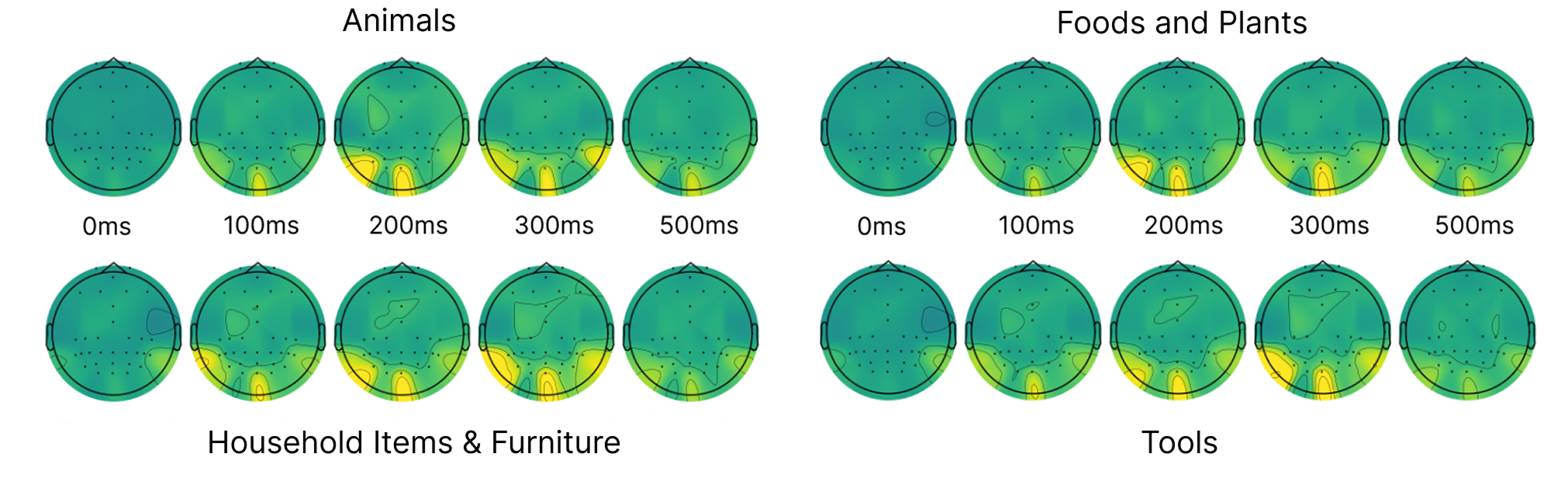
3. Verifying the Signal: Where is the model looking? To trust our decoding results, we needed to know where our model was pulling its signal from. We used “saliency maps” as an interpretability tool to visualize what the model pays attention to. Across all image categories, it consistently homed in on the locations at the back of the head around 200 milliseconds post-stimulus. This matches established neuroscience understanding for visual processing. It confirms that even on low-cost consumer hardware, deep learning models are anchoring their predictions in true visual cortex activity rather than experimental artifacts.
We trained various deep learning methods to reconstruct original images from EEG data. To measure true visual quality, we had human reviewers test the outputs by visually matching the reconstructions to the originals (2AFC identification task). Using our ENIGMA architecture, these human raters achieved an 83.06% identification accuracy on the lab-grade THINGS-EEG2 dataset, compared to a 65.43% accuracy on the Alljoined-1.6M dataset.

Well-established neural scaling laws demonstrate that deep learning models predictably improve in a log-linear fashion as dataset size increases. We tested whether these same laws applied to low-SNR brain data by training the ENIGMA model on progressively larger subsets of our dataset. We found that decoding performance increased linearly with the log-trial count and showed no signs of saturating at the full dataset size.
As expected, models trained less efficiently on the consumer-grade recordings due to the inherently noisier signals of lower-cost hardware. Yet, the affordability of these devices allows for data collection on a massive scale, enabling sheer volume that partially compensates for reduced signal clarity.
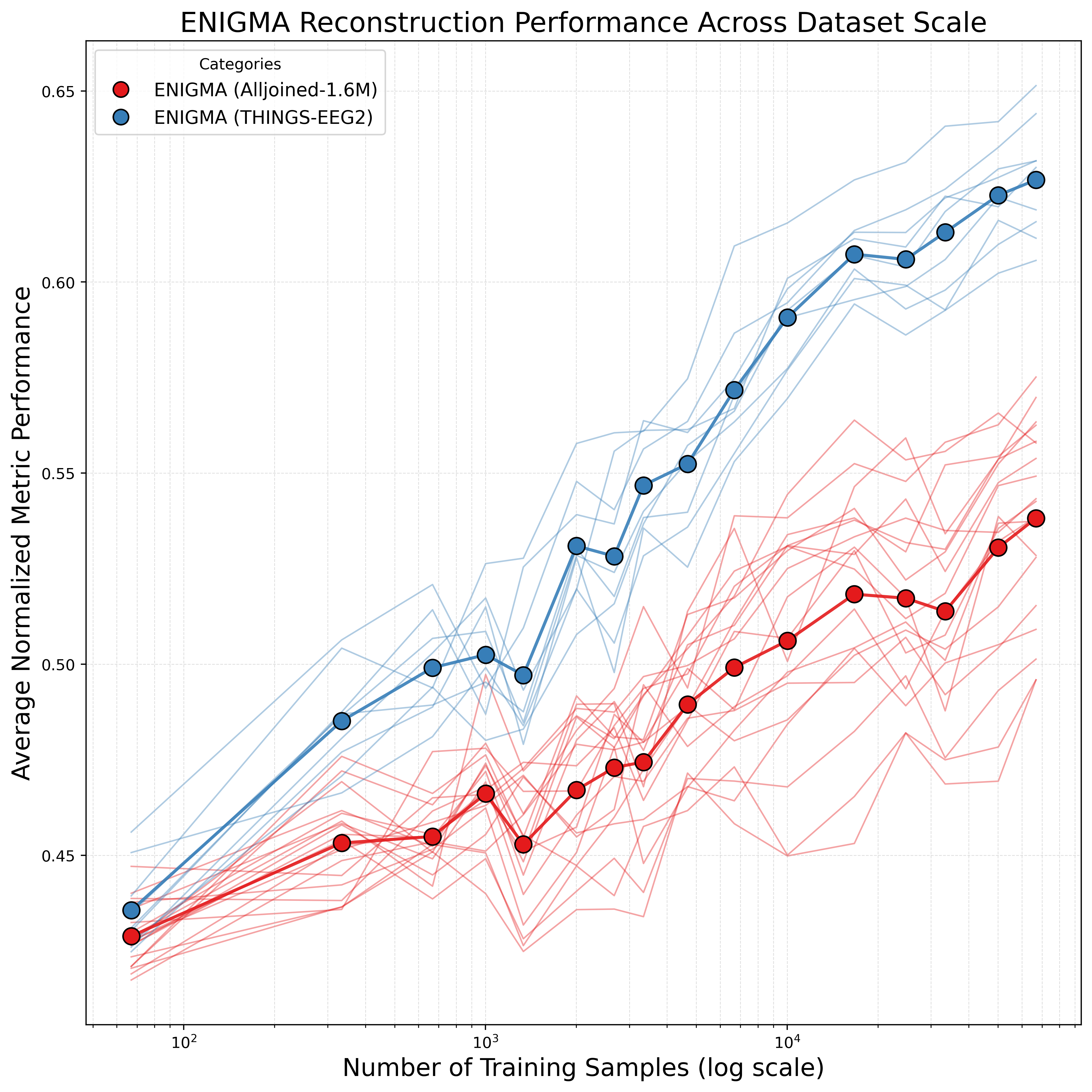
Historically, breakthroughs in understanding the brain have been bottlenecked by the prohibitive costs of pristine data collection. Alljoined-1.6M explores an alternative paradigm by optimizing instead for massive scale and hardware accessibility. We demonstrate that scale alone can enable advanced semantic decoding and image reconstruction on $2,200 hardware, proving there is still valuable signal in lower-quality data.
However, our findings also strongly advocate for improving data quality and collection techniques before scaling naively. We note that contact impedance and amplifier quality explain the poor scaling performance on consumer EEG hardware, leading to a severe drop in scaling efficiency. In fact, the performance of ENIGMA trained at the absolute limits of our consumer-grade dataset is matched by a lab-grade BrainVision system using about 23x less data.
To unlock the real-world potential of neural decoding, we need the ability to extract highly expressive, semantically rich data using hardware that is both scalable and of uncompromising quality. Moving forward, our internal efforts are entirely focused on this intersection. At our company, we are actively pursuing multi-modal experiments designed to truly decode thought, maintaining a strict, rigorous focus on improving data quality and fundamentally understanding where the true signal originates.
We are very excited to share the Alljoined-1.6M dataset with the research community to build stronger intuitions for exploring high-level semantic decoding on consumer-grade hardware.
To isolate the variables driving the performance gap between the datasets, we analyzed specific hardware differences.
Electrode Density (64 vs. 32 channels)
We performed an ablation analysis to evaluate how channel count affects decoding performance by sub-sampling the 64-channel baseline dataset while maintaining coverage over the occipital cortex.
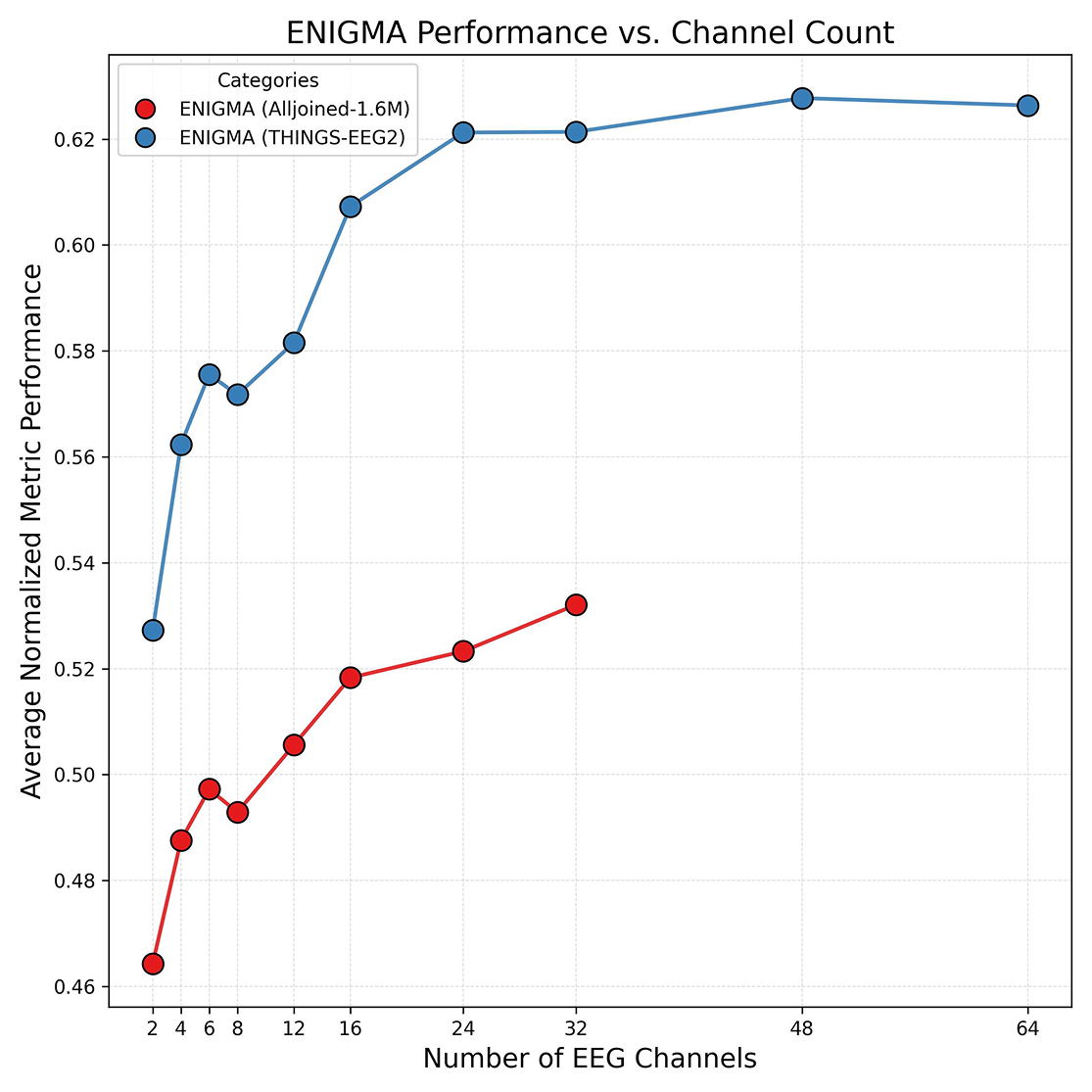
While performance drops with fewer channels, it is not the primary factor explaining the dataset differences. Crucially, performance gains began to drop off after 24 channels. This suggests future real-world BCIs might achieve robust decoding performance with highly streamlined channel arrays.
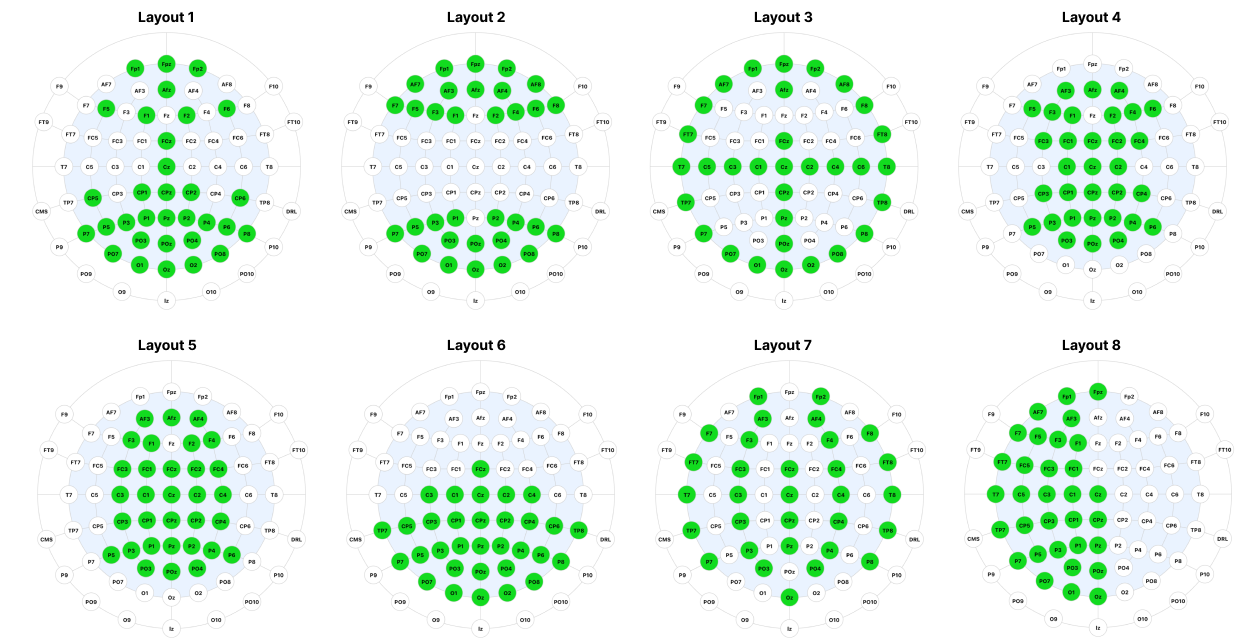
Furthermore, our experiments with 32-channel configurations revealed that optimal layouts require strategic coverage of both the occipital and the ventral streams to capture the specific spatial nuances of semantic object recognition. In this experiment, Layout 1 performed the best.
The performance disparity is fundamentally driven by contact quality and hardware noise. Scalp EEG signals are extremely faint, typically ranging from 10 to 100 microvolts (µV).
Taken together, this variance in noise and contact quality significantly degrades sample efficiency at scale. By the upper bounds of our 1.6M-trial dataset, the consumer-grade hardware proved over 20x less data-efficient than the lab-grade baseline for reaching equivalent performance.
Today, we are introducing NOVA (Neural Observations of Video-evoked Affect), a large-scale dataset of emotion-evoking videos paired with EEG recordings.
Today, we are formally introducing Alljoined-1.6M, a large EEG-image dataset comprising over 1.6 million visual stimulus trials collected from 20 participants on consumer-grade hardware.

Today, we are introducing ENIGMA (EEG Neural Image Generator for Multi-subject Applications). ENIGMA is a new multi-subject decoding model that reconstructs seen images from EEG signals with state-of-the-art accuracy.