Decoding Emotion from EEG: Introducing NOVA
Today, we are introducing NOVA (Neural Observations of Video-evoked Affect), a large-scale dataset of emotion-evoking videos paired with EEG recordings.
Bianca Oliveri
2026-05-25
Emotions shape perception, guide decisions, and structure thought. They form the intimate undercurrent of our cognition, yet are notoriously elusive and difficult to articulate. Our emotion decoding research seeks to address this paradox by developing new ways to externalize and communicate emotional experiences.
Today, we are introducing NOVA (Neural Observations of Video-evoked Affect), a large-scale dataset of emotion-evoking videos paired with EEG recordings. NOVA contains:
This makes it one of the largest EEG-Emotion datasets in the field. Using the NOVA dataset, we demonstrate state-of-the-art decoding performance of up to 75% accuracy with a single-subject model on a six-way emotion classification task (chance = 16.7%). This blog outlines the trajectory of our preliminary research, highlighting two key elements that drive our performance: label quality and signal representation.
At its core, this project echoes Alljoined’s ethos of building a human-centric future for AI and BCIs. Importantly, human intelligence is not purely logical or symbolic; it is embodied and intuitive. If AI systems are to meaningfully collaborate with us, they must interface with this dimension of experience. We aim to build adaptive systems that not only understand what you say but also empathize with how you feel – infusing artificial intelligence with emotionally-grounded human intelligence.
Furthermore, linguistic communication reduces nuanced and amorphous thoughts into diluted word representations. In recording the neural signals of emotional states, we strive to access the raw patterns of the experience itself. This opens the door to unfiltered forms of representation that will allow people to express themselves more authentically and understand one another on a deeper level.
After surveying emotion decoding research, we found much of the recent high-profile work in the space to be fragile and confounded. Some reported accuracies relied on subtle methodological issues that inflate performance without reflecting real-world capability. Because Alljoined wants to build robust models that will work in real-world applications, we decided to design NOVA from scratch, with rigorous experimental controls and honest evaluation.
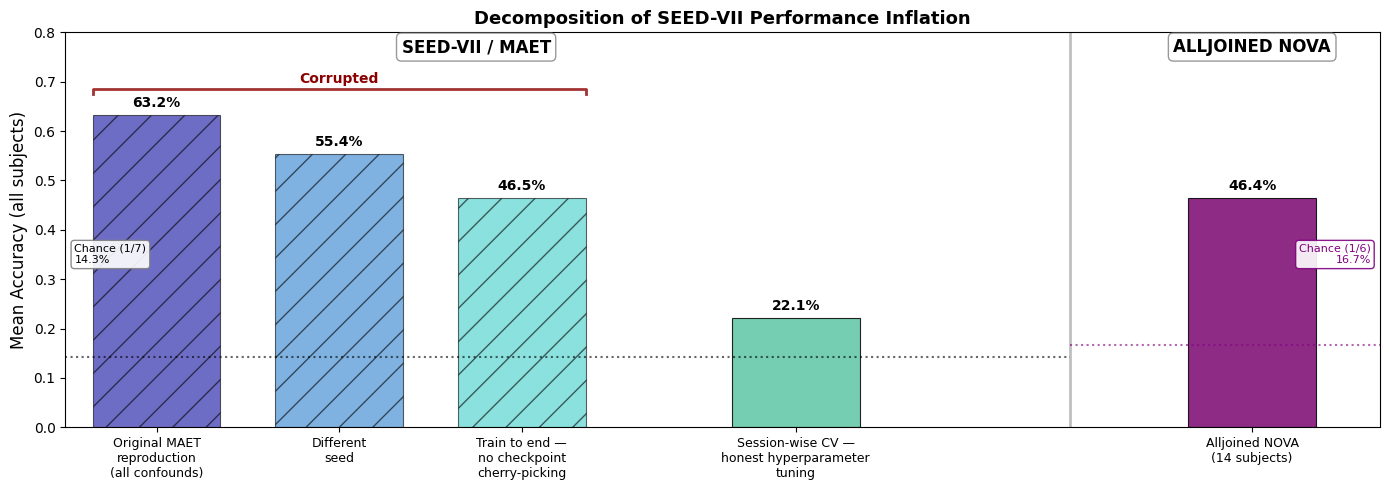
Figure 1. Results replicating work from the BCMI group at Shanghai Jiao Tong University, using SEED-VII, one of their latest datasets of EEG data of video-evoked emotions. Using the code sent to us by the paper's authors, we identified a few points in the model architecture that were fragile. After removing confounds, their transformer-based MAET model performance drops significantly- with our NOVA dataset outperforming it considerably using a simple ridge regression model. NOVA accuracy here is the average of session-wise cross-validation on our 14 single-subject models. To fairly evaluate SEED/MAET, we cross-validated across sessions rather than folds, removed block-wise hyperparameter tuning on the test set, removed test-set-determined early stopping, and removed overfitting to specific random seeds.
The very qualities that make emotion an interesting research topic also make it difficult to measure. Emotions are fundamentally intertwined with perception, creating a self-reflexive limitation; in describing our emotions, we are trying to perceive a facet of perception itself. As a result, subjective reports are inherently unreliable: participants struggle to label their emotional states, and descriptions often diverge from physiological or behavioral observations. This metacognitive problem highlights exactly the kind of obscured communication that Alljoined seeks to solve. However, unraveling this problem requires confronting it in our own research methods first.
Unlike many other decoding tasks, which have a clear external ‘ground truth’, an accurate reference is inaccessible in emotion research. We know exactly what a participant sees when viewing a visual stimulus, but what a participant feels when viewing a movie scene remains largely opaque. The layers of mixed texture and tone of an emotional experience are unlikely to be captured by a single label or coherently conveyed in a participant’s description.
This matters because accurate labels are a critical component of efficient machine learning. In supervised learning, models are trained by pairing each datapoint (EEG epoch) with a label. The model ingests many instances of brain activity associated with a given emotion label, for example, all the EEG recordings of a participant viewing ‘sad’ videos. The model tries to learn the neural signature of ‘sad’ by identifying patterns that are consistent across these instances. However, if self-reported emotion labels diverge substantially from the neural activity of the participant's true emotional state due to the inherent difficulty of introspection, the signal the model is trying to learn becomes incoherent.
This is a major reason for the nascent state of emotion decoding research. The label problem cannot be fully solved, but it can be mitigated. NOVA attacks it from two angles: first, the sheer volume of the dataset (3,408 EEG-Emotion-Video pairs) allows consistent signal to overcome outlier noise, and second, through high-quality stimulus curation.
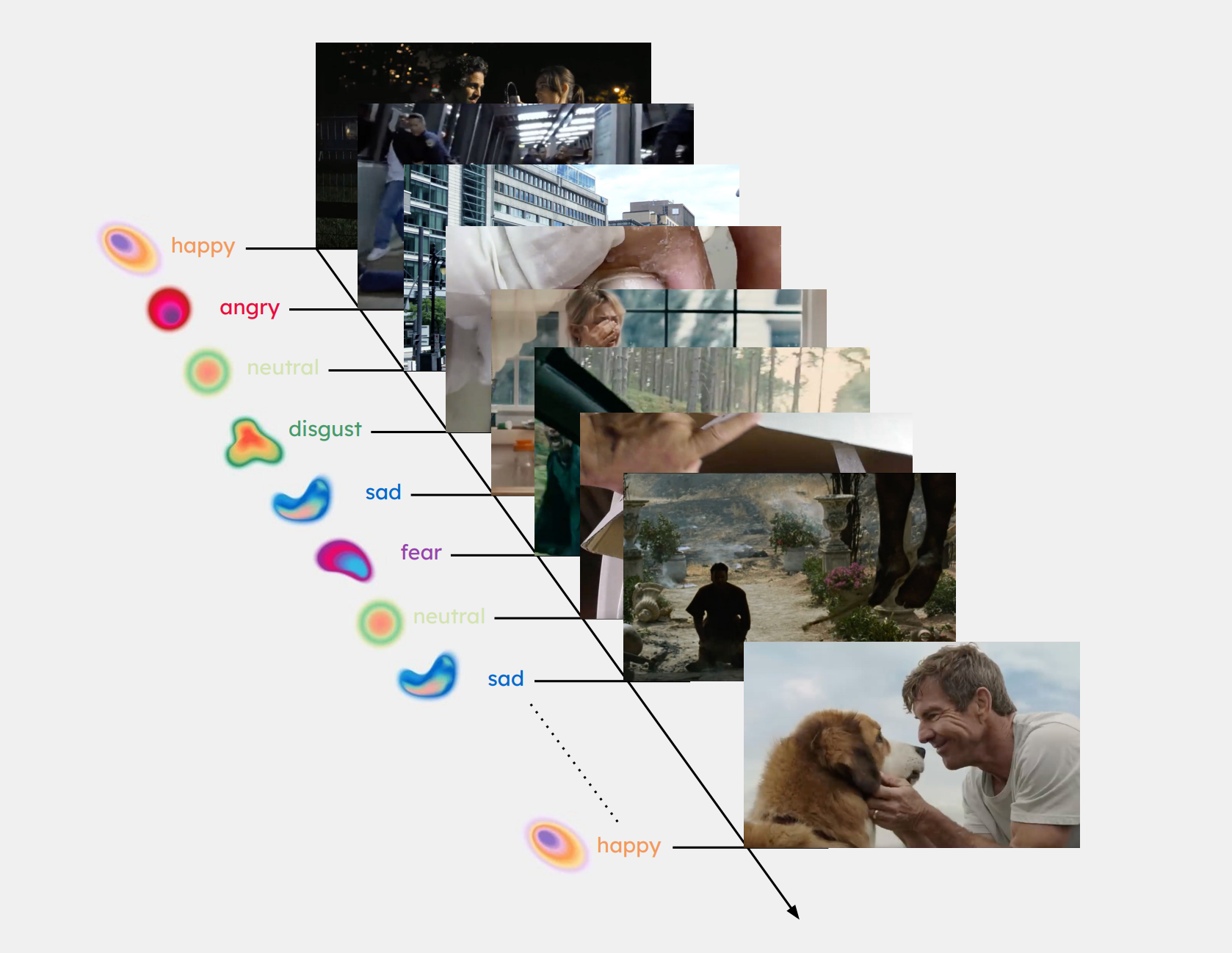
Addressing the label problem requires maximizing the likelihood that a video reliably evokes the emotion it was designed to evoke. This is a challenging endeavor, especially when participants are of varying ages, cultures, and backgrounds. For example, a video of a dog being abandoned may make one participant feel sad for the dog and another participant feel angry at the negligent owner. Even on an individual level, emotional responses are often mixed and difficult to disentangle. For this reason, thoughtful curation is a critical component of NOVA.
The dataset’s 408 videos are curated through a rigorous three-stage review process: research assistants submit YouTube videos and movie scenes as candidates, critique one another’s selections, and only those that survive a final screening are admitted to the dataset. This process tests if stimuli universally elicit strong, discrete emotional responses across a variety of people. The videos that make it into the dataset are then incorporated into our experiments.
Each video is 1-5 minutes long, spanning 6 coarse categories: Anger, Sadness, Fear, Disgust, Happy, and Neutral (control). After multiple iterations, we landed on an experimental paradigm in which each ~1hr 15 min session contains 24 videos, 4 from each emotion category, presented in a shuffled block design. Between videos there are breaks for the participant to reset to baseline before proceeding to the next video. This randomized design prevents emotional carryover between videos while minimizing burnout as much as possible.
After each video, the participant rates how intensely they felt each of the 6 emotions on a scale of 1-10. Subjective labels are distilled from these ratings to provide a pseudo-ground-truth label. We achieve an 83% alignment rate between participants’ subjective labels and the intended target emotion, demonstrating that our videos reliably elicit the intended emotions across a variety of people.
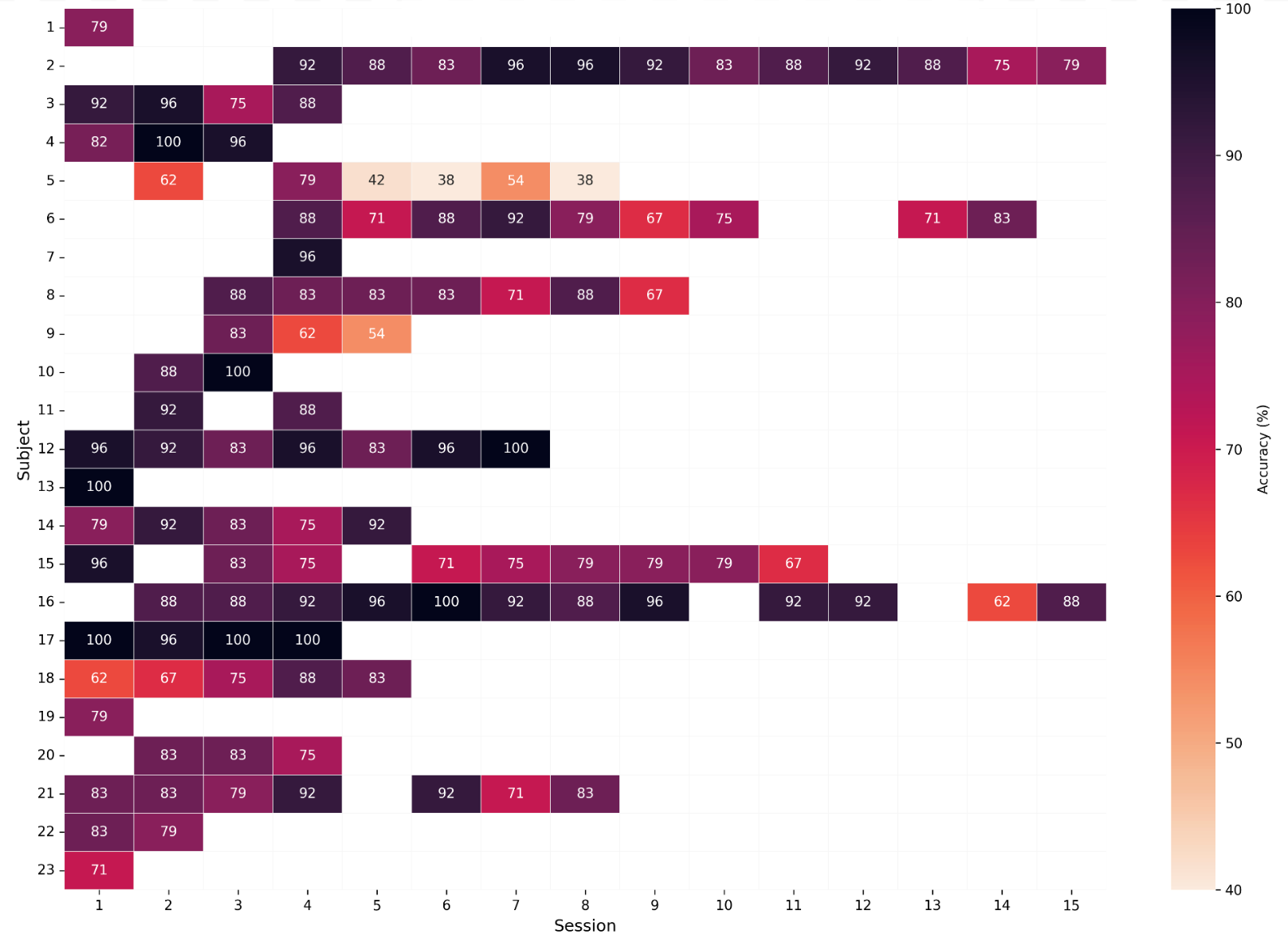
Figure 2: Heatmap of dataset accuracy (“correct” when subjective emotion label == intended emotion label).
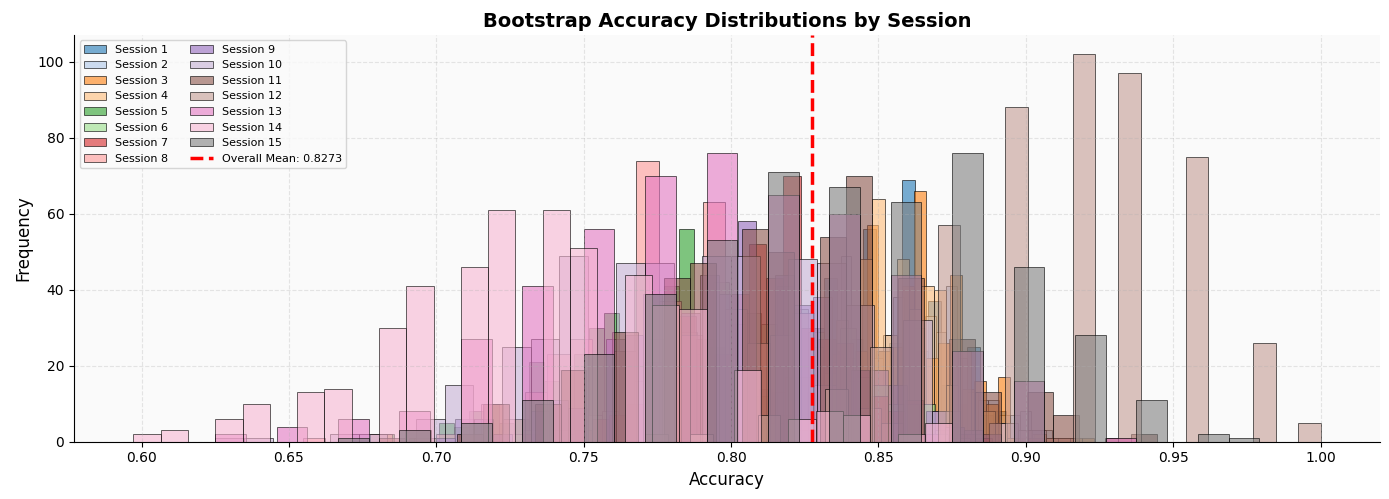
Figure 3: Bootstrap Accuracy of Subjective Label Alignment.
Reliable labels are one half of our supervised learning equation; the other is how we extract meaningful signals from raw EEG data. EEG signals capture the spatio-temporal patterns of voltage oscillations across the scalp. The raw signal is rich, but how you represent it for modeling has a significant impact on what patterns are learnable. Some feature spaces preserve and highlight more relevant aspects of EEG’s dynamic signal than others.
Much prior emotion research applies Differential Entropy (DE), a technique that compresses the signal into power estimates across five discrete frequency bands. While DE is computationally convenient, it discards much of the information that distinguishes emotional states from one another. In our analysis, we found the more expressive Power Spectral Density (PSD) operation to be a better-suited feature space. Rather than binning power into a handful of frequency buckets, PSD retains the full spectral fingerprint with up to 40x the granularity of DE. DE gives you ~5 features per electrode channel; PSD gives you ~200+.
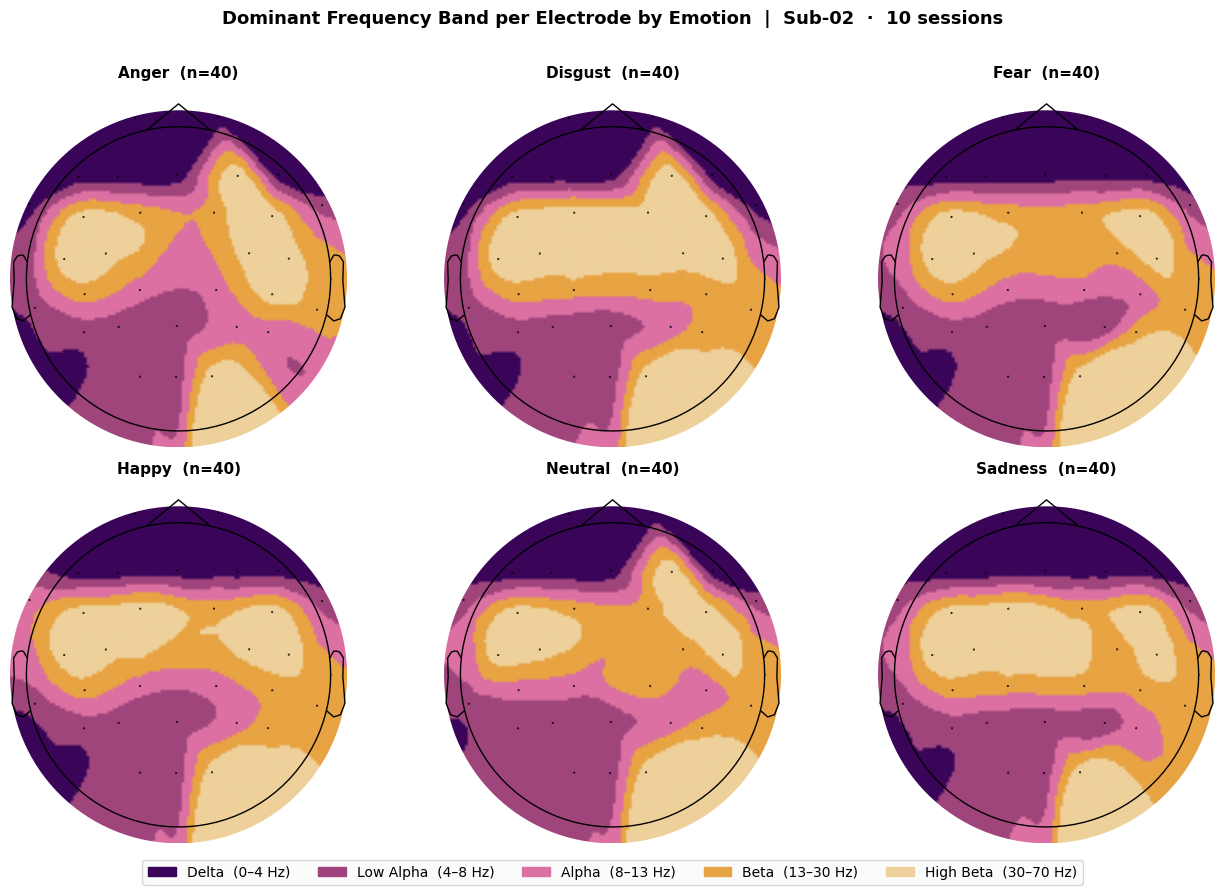
Figure 4: Dominant frequency band distributions per emotion. Measured on one participant, averaged across 10 sessions. Each electrode is assigned to one of the 5 frequency bins, depending on which frequency band has the most power concentrated at that site.
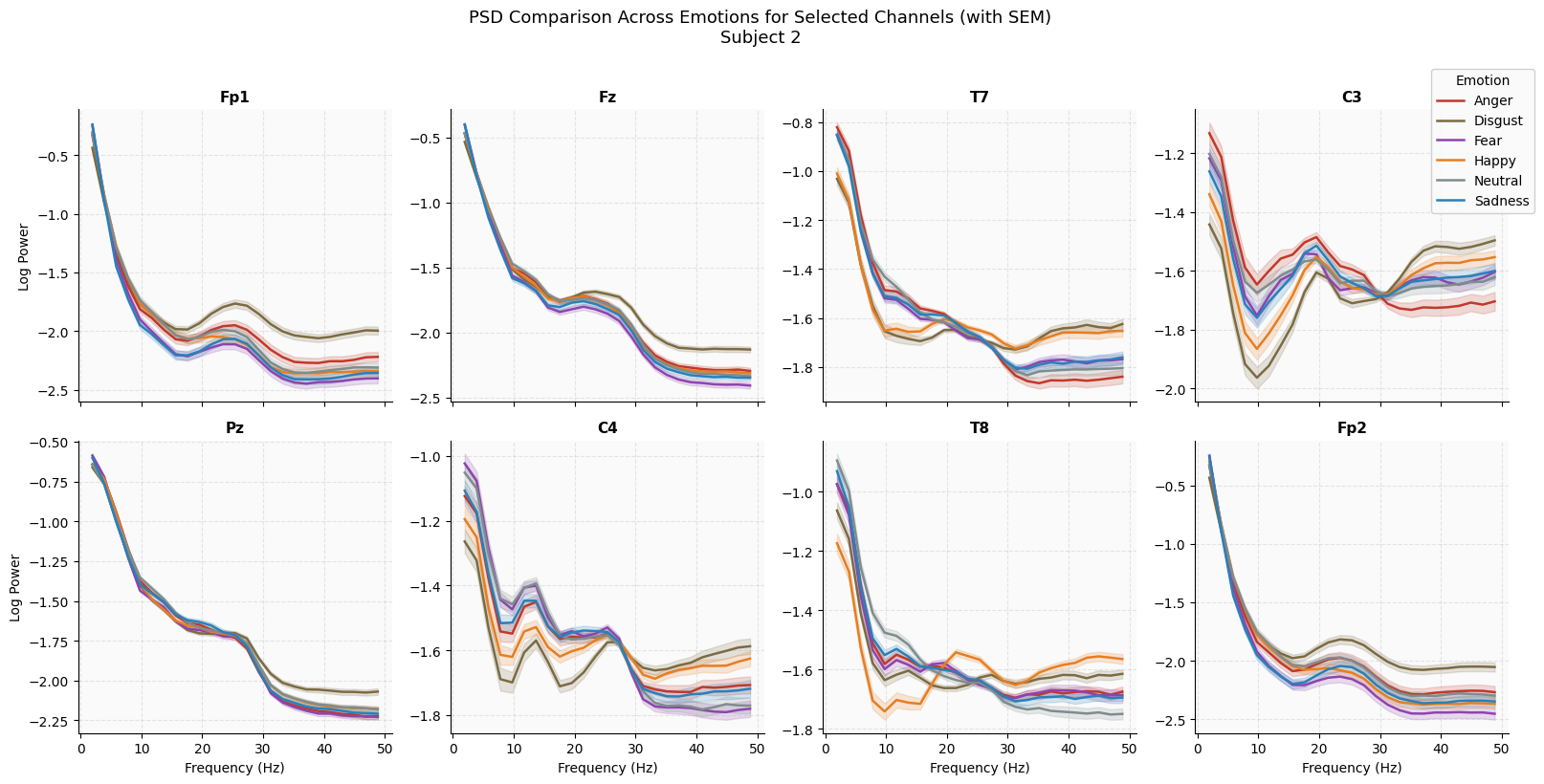
Figure 5: Visualization of how emotions are separated by PSD signatures across select electrodes. Note how power at each frequency range at each electrode is preserved.
As an illustrative technique, we use a simple ridge classifier to showcase the decoding potential of NOVA. Each trial (video) is represented as a vector of ~6,231 PSD features across 31 electrode channels. Across many trials, the model identifies which frequencies at which electrode locations are reliably elevated or suppressed during a given emotional state. It then applies these learned signatures to predict the emotion class of a novel, unlabeled EEG segment.
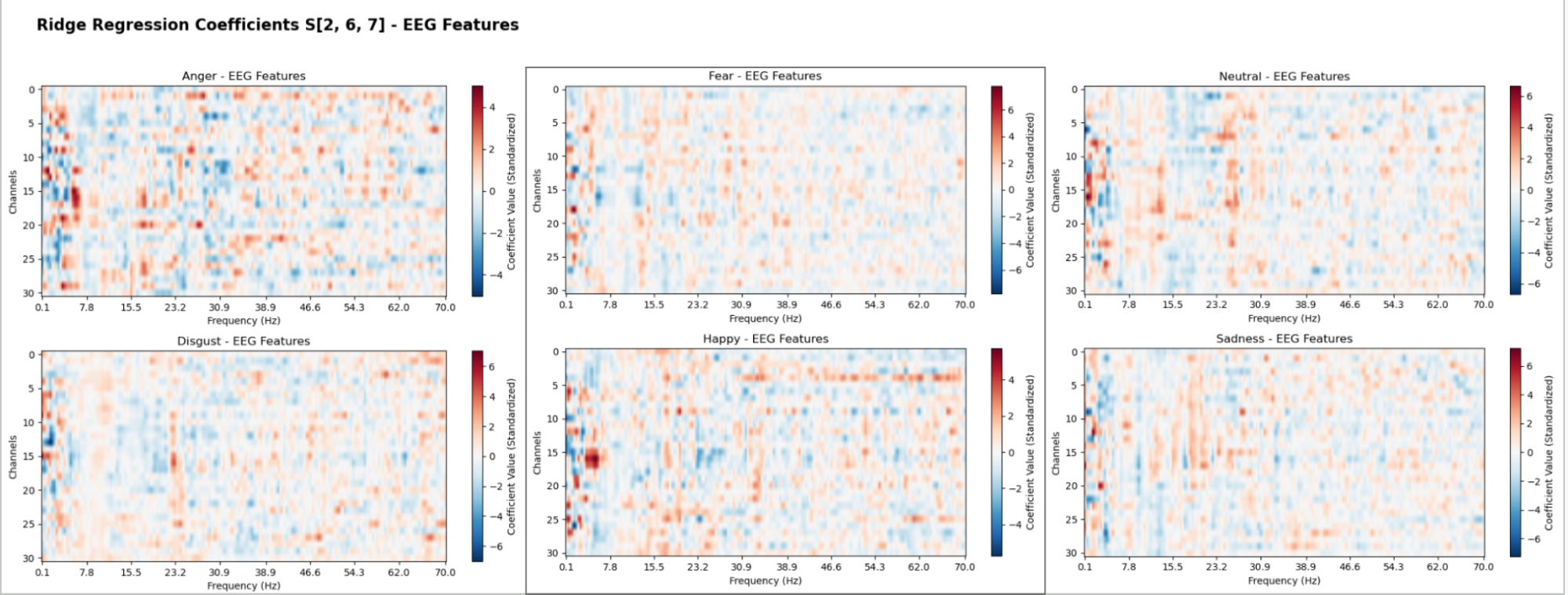
Figure 6: Per-class ridge regression coefficients mapping which channel-frequency features are most predictive of each emotional state. The ridge model assigns each of the ~6,231 (channel × frequency) features a coefficient per emotion class, where positive weights (warm colored) indicate elevated power at that feature increases the likelihood of that class; negative weights (cool colored) suppress it.
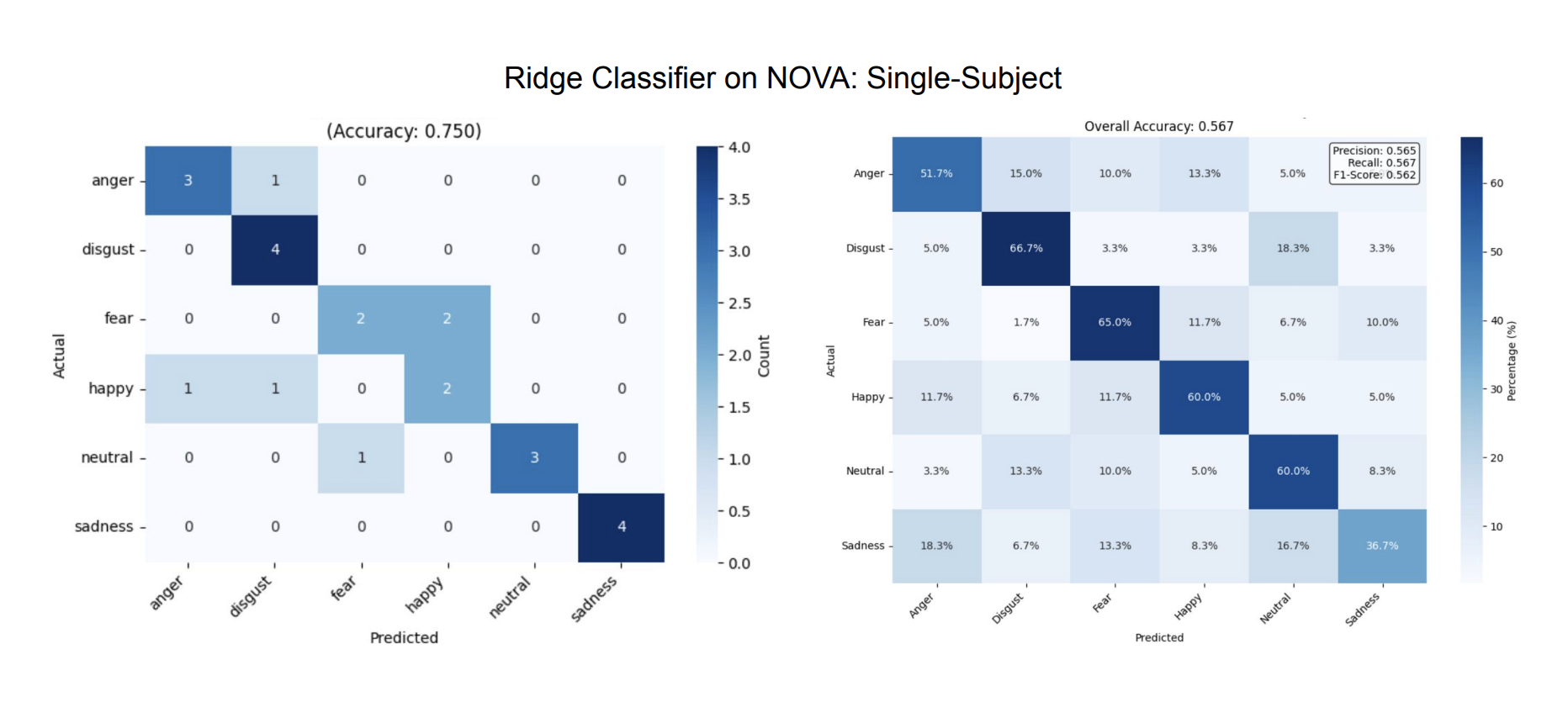
Figure 7: The first confusion matrix shows a performance of 75% accuracy on a single-subject model on 14 sessions of training data, tested on one held-out session. The second matrix shows a performance of 57% accuracy on the same single-subject model, session-wise cross-validated on all 15 sessions of data.
On this six-way classification task, random guessing yields 16.7%. We get up to 75% accuracy with a single-subject model. On average, across all participants, using session-wise cross-validation we get 46% accuracy. Using the simple ridge algorithm here lets the quality of the dataset speak for itself; impressive performance is achieved not with complex model architecture, but through deliberate experimental design and high-quality data. Careful analysis and iteration allowed us to distill where meaningful signals reside and how to represent them. When building robust systems from the ground up, starting with a meticulously clean and optimized dataset is crucial.
One of the biggest bottlenecks in the field of emotion research is the strenuous, draining, and time-intensive process of data collection. NOVA directly helps close this gap, providing a resource for downstream research that extends well beyond our own models.
Emotion is a layered and dynamic problem space, and one of critical importance as Alljoined builds increasingly nuanced representations of internal states. The complexity of this research provided us with deeper insight into how we should approach internal state decoding more broadly. Emotion is difficult to measure, guarantee and isolate. We also observed slow scaling behavior, suggesting we cannot rely on data volume alone to drive performance. For this reason, we believe the emotion data collected in NOVA will become increasingly powerful when integrated with our other ongoing multi-modal research threads.
Our preliminary results demonstrate state-of-the-art performance in EEG-based emotion decoding, laying the foundation for the next generation of affective computing devices and bringing us closer to reading the fabric of inner experience.
Today, we are introducing NOVA (Neural Observations of Video-evoked Affect), a large-scale dataset of emotion-evoking videos paired with EEG recordings.

Today, we are formally introducing Alljoined-1.6M, a large EEG-image dataset comprising over 1.6 million visual stimulus trials collected from 20 participants on consumer-grade hardware.

Today, we are introducing ENIGMA (EEG Neural Image Generator for Multi-subject Applications). ENIGMA is a new multi-subject decoding model that reconstructs seen images from EEG signals with state-of-the-art accuracy.